
The most celebrated problem in theoretical computer science is undoubtedly the P vs. NP problem. Let me explain what it is asking. (If you already know this, feel free to skip the next few paragraphs.) Suppose we have a general type of problem that we wish to solve. (Think of something like determining if a number is prime, or factoring it.) There are many instances of such a problem. (For example, there are lots of numbers out there, and we could ask for each number whether or not it is prime.) Now, suppose we have a computer program that solves this type of problem: it runs for a while, and eventually tells us the answer. The amount of time it takes to run depends on the complexity of the specific problem we give it: for example, we should expect it to take longer to determine whether a very large number is prime than it would take for a small number, although there are some exceptions. (It would be very fast to say that a large number is composite if it is even, for instance.)
For the most part, then, the amount of time it takes to run the program depends on how complicated the particular instance of the problem is. We’ll measure that in terms of the number of characters needed to enter it. So, we can ask how long it takes to determine if an 
Normally, we aren’t particularly interested in exactly how long it takes to run in terms of number of seconds, because that changes from one computer to another. Instead, we’re interested in how the length of time grows as the length of the input grows. We say that a program runs in polynomial time if there is some polynomial 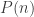

Now, let us consider the notion of NP, which stands for nondeterministic polynomial time. What this means is that, if I magically tell you the answer to a problem (but I might be lying to you), you can check whether I’m telling you the truth in polynomial time. A classic example of this is factoring. If I ask you to factor 51445627, you are unlikely to be able to do that quickly (although there are some very clever algorithms for doing it). But if I tell you that the prime factors are 5689 and 9043, then you can check this quickly, in polynomial time in the length of the original number. Note that all P problems are also NP problems: if you can solve the problem on your own in polynomial time, you can still solve it in polynomial time if I tell you the answer, for example by ignoring my answer.
The P vs. NP problem asks if P = NP. That is, can every problem that can be checked in polynomial time also be solved in polynomial time? Most people believe the answer to be no, but we have made little progress toward a proof.
Note that the property of being in P depends on all instances of the problem. However, computer scientists are a bit different from mathematicians: they don’t usually need to prove things; they just want to get right answers. (Probably not all of them, but that’s my view of it from a mathematician’s world.) So, might it be that there problems that can’t always be solved in polynomial time, but usually can?
This is the subject of Russell Impagliazzo’s very nice survey paper “A Personal View of Average-Case Complexity.” He rather amusingly frames the problem in terms of the famous story about a very young Gauss being asked to sum the numbers from 1 to 100, and the teacher’s subsequent attempts to humiliate Gauss in revenge for his quick solution. (Note: I don’t do that to my students. In fact, I like it when they are clever.)
In it, he includes a definition for an average polynomial time algorithm, which essentially means that if we were to choose a random instance of the problem, we would expect to be able to solve it in polynomial time. But before we can make that more precise, it is necessary to explain what we mean by a random instance of the problem. In order to do that, it makes sense at first to restrict to a given input size 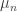
Now, one might ask whether there are any problems for which there exist average polynomial time algorithms but not polynomial time algorithms. Since we don’t know whether P = NP or not, it’s hard to be sure, but one problem that is very strongly believed not to be a P problem is the Hamiltonian path problem. Let us explain what it says.
A path in a graph is a sequence of edges so that each edge (other than the first) starts where the previous one ended. (So that we can imagine walking on it if we were on the graph.) A path is called a Hamiltonian path if it goes through each vertex once, without any repetitions.
The Hamiltonian path problem asks if, given a graph, we can determine whether there is a Hamiltonian path. This problem is definitely an NP problem: if someone tells us that there is a Hamiltonian path and tells us what it is, then we can quickly check whether it actually is. (However, if someone tells us that there is no Hamiltonian path, it is not clear how we would verify that quickly, and indeed we expect not to be able to do so.)
It is widely believed that the Hamiltonian path problem is not a P problem; in fact, if it were, then we would also have P = NP, since it is possible to convert any NP problem quickly into a Hamiltonian path problem.
So, we believe that we can’t solve the Hamiltonian path problem quickly in general. But what about for most cases?
In order for that question to make sense, we need to put a probability distribution on graphs with 
So, let’s fix a
- Choose a potential starting point and a potential ending point. (There are only a polynomial number of pairs to choose, so we can run through all such pairs in polynomial time.) Try to make a Hamiltonian path by making a path from the starting point that’s as long as possible, just by trying to add one vertex at a time. Once we get into trouble, do the same thing starting with the ending point. Try to make minor modifications to splice these two pieces together.
- If that doesn’t work, try to show there is no Hamiltonian path. To do this, identify troublesome vertices: the ones that have relatively small degree. See if there is a contradiction involving these problem vertices.
- If that doesn’t work, simply check every possible path and see if it gives a Hamiltonian path.
Steps 1 and 2 can be done in polynomial time; it is only step 3 that can’t. But it turns out that we won’t reach step 3 very often, because most of the time the algorithm will have finished after step 1 or 2.
Okay, so it’s an example, although I don’t find it particularly satisfying: as
So, I am curious to know whether there are more interesting examples of problems with average polynomial time algorithms but that are not expected to have worse-case polynomial time algorithms.
