
I hadn’t played a tournament since May, when I had a disastrous tournament and lost four games before withdrawing in disgust. My tournament this weekend was mostly mediocre, except for one game, in which I scored my first win against an IM. (It was a useful moment to start playing like a master myself.) Naturally, that’s the one I’m going to show.
Simon Rubinstein-Salzedo (2060) vs. IM Ray Kaufman (2354)
1. e4 e5 2. Nf3 Nc6 3. d4 exd4 4. Nxd4 Nf6 5. Nxc6 bxc6 6. Bd3
Previously, I had played the main line of the super-sharp Mieses variation of the Scotch, which goes 6. e5 Qe7! (not Nd5) 7. Qe2 Nd5 8. c4 and black plays either 8…Nb6 or 8…Ba6. The game could continue something like this. However, this is the sort of game I’d rather watch than play, being a Boring Positional Player and all that.
So, the quieter and more civilised 6. Bd3 line suits me better and allows me not to memorize gobs of theory, although objectively it offers white somewhat fewer prospects.
6…d6
This move surprised me. I usually see 6…d5, after which I would continue with 7. exd5, since after 7. e5 Ng4 8. 0-0 Bc5, black is going to be the one who has more fun for a while. Here’s the sort of thing that can go wrong for white. But after 7. exd5, white is slightly better, since eir pawn structure is slightly better.
7. O-O Be7 8. Qe2
Okay, 8. Nc3 is more natural (and more common), but I am not yet sure how I want to develop my queenside pieces: do I put my bishop on g5, or on b2? Do I develop the knight to c3 or d2? If c3, should I play c4 first? But I am certain that I will have to move my queen out at some point, so I might as well do that now and think more about what to do about the rest of my pieces.
8…O-O 9. b3 Nd7!
A very sensible redevelopment. My opponent is planning to play Bf6 next move (whether I play Bb2 or not) and later plant the knight on c5 or e5, where it’s sort of annoying.
10. Bb2 Bf6 11. Bxf6 Qxf6 12. Nd2 Re8 13. f4 Nc5 14. Rae1 Qc3

I think both sides can be relatively satisfied with this position. It’s about equal, and there isn’t anything obvious that either side has to do, so we can just play chess and try to come up with the best ideas we can.
15. Nf3 a5
Okay, so his plan is to weaken my queenside pawns or else open the a-file for his rook. Very sensible. Playing 16. a4 felt wrong, since after 16…Nxd3 17. Qxd3 Qxd3 18. cxd3 Rb8, I’ve given my opponent a target for no good reason. One possibility (depending on where the queens are at the time) is to play b4 after black plays a4 and then follow up with a3 (unless black plays it first). Then we each have a bunch of structural weaknesses that probably balance out. Another option (which the computer recommends) is to play e5 and focus on black’s c-file weaknesses. The position remains balanced.
16. Qd2 Qb4
I’d be satisfied with exchanging queens on d2, but not on b4.
17. c3 Qb6
Not 17…Qa3? 18. Bb1!, and after an eventual e5, the white bishop will be a very dangerous piece.
18. Rf2
But not 18. Kh1? when after 18…a4! I don’t have a satisfactory way of dealing with Nxd3 and Ba6.
18…Bg4

Really? That way? I was mostly expecting the bishop to move out to a6 or b7 at some point.
19. Nd4
Aside from the fact that I don’t want to allow him to capture on f3 and slightly damage my kingside pawns (which wouldn’t be too big of a problem), this introduces some interesting tactical possibilities in the next few moves.
19…Nxd3 20. Qxd3 a4
It looks like black is making progress on the queenside. But there’s a small problem.
21. f5!

Suddenly the bishop is in serious danger of getting trapped. The only way out is to play f6 followed by Bh5 and Bf7. Note that the move order is very important: After 21…Bh5? 22. Qh3! g6 23. g4 wins the bishop.
21… axb3!
Unbelievable! He’s just going to let me trap his bishop? Yes, because if I start to trap it with 22. h3, then after 22…bxa2 23. Ra1 c5 24. Nc2 Qb1 25. Rf1 c4 26. Qd2 Qb6 27. Kh1 Bh5 28. g4 Bxg4 29. hxg4, black has lots of compensation for the piece and is better (but possibly not winning). Of course, I didn’t see the whole line, but I saw enough to realize that it was sensible to stabilize the queenside before dealing with the bishop.
22. axb3! c5?
There’s no need to help me reroute my knight to a better square. Now white is substantially better.
Just a few moves ago, we had a relatively quiet position, where it seemed hard for either side to make any seriously dangerous threats. Now the position is very sharp, and seemingly minor inaccuracies like c5 can be fatal.
23. Nc2!
23. Nb5 was briefly tempting, but my move helps the knight get to the square it actually wants to reach: d5.
23…f6?

Of course, I was expecting this move, but it runs into tactical problems…that I completely overlooked. Better was to sacrifice the bishop with 23…Qxb3, which gives black some compensation for the piece, but probably not enough.
24. Ne3?
Looks sensible, but after 24. Qc4+! black is in serious trouble and possibly just lost. The obvious move 24…Kh8? just loses to 25. Ne3!, when the bishop is lost for very little compensation. Better is 24…Kf8, but after 25. e5!, black’s problems continue: 25…Bh5? loses outright to 26. e6, but after 25…Rxe5 26. Rxe5 dxe5 27. Qxg4 Qxb3, black can muddle on. Instead, the computer’s choice is 24…d5, but white just captures with the queen and is up a pawn for no compensation.
After my mistake, black is okay again. At least, in theory: in practice, white’s position is much easier to play.
24…Bh5 25. Nd5 Qb7 26. Qg3!

No more messing around; it’s time to attack the king.
26…Kh8
I was expecting this move, but 26…Kf8 avoids some of black’s later problems. I suppose he missed or underestimated my 28th move.
27. Qh4 Bf7?
What else is he supposed to do? 27…c6! Then after 28. Nxf6 gxf6 29. Qxh5 Qxb3, the position is equal. Now white is winning.
28. Nxf6!

This is just winning. I wasn’t so confident during the game, but I couldn’t find a satisfactory defense for black, so I had to play it. But on the other hand, what am I doing!?!?! I’m supposed to be a Boring Positional Player; why am I sacrificing my pieces? (And why does this happen in quite a few of the games I have annotated on my blog recently?)
28…gxf6 29. Qxf6+ Kg8 30. Rf4
The computer tells me that 30. Rf3 is even stronger. Whatever.
30…h5
30…Qxb3 puts up a bit more resistance, but it’s still lost.
31. Qh6
New mate threat: f6 and Qg7.
31…c6 32. Rf3 h4 33. Rf4 Black resigns

Of course, I’m thrilled with the result of this game, but I’m also quite satisfies with the game itself. It was one of the most interesting games I’ve played, and I’m happy with how I played, even if I did miss a very powerful move on move 24.
I’m hoping this is only the first of many wins over masters on my quest of chess improvement.
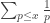 , where the sum is taken only over primes
, where the sum is taken only over primes  . His method of discovering this was rather elegant, even if his lack of respect for divergent series may look horrifying to a modern mathematician. It was already known earlier that the harmonic series grows like
. His method of discovering this was rather elegant, even if his lack of respect for divergent series may look horrifying to a modern mathematician. It was already known earlier that the harmonic series grows like 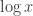 ; that is,
; that is,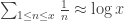 ,
, .
.
 . (This formula has a delightful interpretation as an analytic formulation of the fundamental theorem of arithmetic.) Since neither side of the above formula makes sense when
. (This formula has a delightful interpretation as an analytic formulation of the fundamental theorem of arithmetic.) Since neither side of the above formula makes sense when 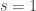 , Euler did the most logical thing possible and set
, Euler did the most logical thing possible and set  .
.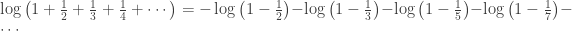 ,
,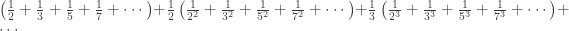 .
. .
. .
. by taking limits and being careful with error terms like a modern mathematician would do. But that wasn’t a necessary part of the culture in the 18th century.
by taking limits and being careful with error terms like a modern mathematician would do. But that wasn’t a necessary part of the culture in the 18th century. , using a quick and easy computation. Since I’m a rebellious mathematician, I did the following computation on the front of an envelope.
, using a quick and easy computation. Since I’m a rebellious mathematician, I did the following computation on the front of an envelope.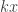 , for some
, for some 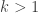 , and let us write
, and let us write 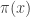 for the number of primes up to
for the number of primes up to  ,
, is not much bigger than 1, then each summand on the left is roughly
is not much bigger than 1, then each summand on the left is roughly  . The goal is now to determine
. The goal is now to determine  . We have
. We have .
.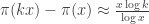 .
. and again taking the first term of the power series for the logarithm (that seems to be the name of the game today), we obtain
and again taking the first term of the power series for the logarithm (that seems to be the name of the game today), we obtain .
.
 .
. . The first few are easy:
. The first few are easy:
 .
. , and we compute
, and we compute  , where
, where  and
and 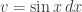 , so that
, so that![I_n = \int_0^\pi \sin^n x\, dx = \left[-\sin^{n-1} x\cos x\right]_0^\pi +\int_0^\pi (n-1)\sin^{n-2} x\cos^2 x\, dx](https://s0.wp.com/latex.php?latex=I_n+%3D+%5Cint_0%5E%5Cpi+%5Csin%5En+x%5C%2C+dx+%3D+%5Cleft%5B-%5Csin%5E%7Bn-1%7D+x%5Ccos+x%5Cright%5D_0%5E%5Cpi+%2B%5Cint_0%5E%5Cpi+%28n-1%29%5Csin%5E%7Bn-2%7D+x%5Ccos%5E2+x%5C%2C+dx&bg=ffffff&fg=333333&s=0&c=20201002)
 .
.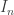 , we get
, we get  . Now it’s easy to compute more of the
. Now it’s easy to compute more of the 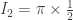
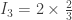

 ,
,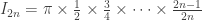
 .
. ,
,  , since
, since 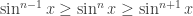 whenever
whenever 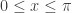 . Furthermore, since
. Furthermore, since 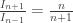 , this means that eventually
, this means that eventually 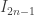 and
and  get very close together. So
get very close together. So ,
,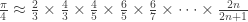 .
. , but it doesn’t add much value, in my opinion, to do that here.)
, but it doesn’t add much value, in my opinion, to do that here.) .
.
 , a middle child will have rank
, a middle child will have rank  . Hence, in the above tree, A and F have rank 0; B, E, and H have rank
. Hence, in the above tree, A and F have rank 0; B, E, and H have rank  ; D has rank
; D has rank 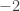 ; C and G have rank 1.
; C and G have rank 1. of them. This isn’t too surprising, since the famous Catalan numbers
of them. This isn’t too surprising, since the famous Catalan numbers  enumerate binary trees (see Richard Stanley’s Enumerative Combinatorics Volume 2, Exercise 6.19(c)).
enumerate binary trees (see Richard Stanley’s Enumerative Combinatorics Volume 2, Exercise 6.19(c)).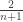 .
. ways to get from
ways to get from 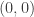 to
to  by taking unit steps either up or to the right, and
by taking unit steps either up or to the right, and 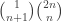 ways of doing this without every going below the diagonal line
ways of doing this without every going below the diagonal line  .
.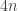 edge-germs emanating from all the genuine nodes, put together. There a total of
edge-germs emanating from all the genuine nodes, put together. There a total of 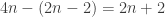 phantom edge-germs, or $2n+2$ phantom nodes.
phantom edge-germs, or $2n+2$ phantom nodes.
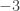 , and so on. Here is a table with the first few values.
, and so on. Here is a table with the first few values.

 in this case. But in fact, that’s always true: we pass
in this case. But in fact, that’s always true: we pass  phantom nodes and
phantom nodes and  edges between genuine nodes. The former decrease the count by one, and the latter increase it by 1, so we have a net
edges between genuine nodes. The former decrease the count by one, and the latter increase it by 1, so we have a net  by tracing the entire tree. So, we always start at
by tracing the entire tree. So, we always start at 
 , and so the proportion of all ternary trees which are skew is also
, and so the proportion of all ternary trees which are skew is also 
 edges and
edges and 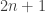 vertices. We can add in the phantom neighbors to obtain
vertices. We can add in the phantom neighbors to obtain 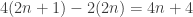 phantom nodes. The goal would be to show that it is possible to hang the picture up from each one of the phantom nodes, so that each one leads to a suitable lattice lath, and of those, exactly 4 of them don’t go below the diagonal. But I don’t know how to do this, so I’d be interested to hear suggestions.
phantom nodes. The goal would be to show that it is possible to hang the picture up from each one of the phantom nodes, so that each one leads to a suitable lattice lath, and of those, exactly 4 of them don’t go below the diagonal. But I don’t know how to do this, so I’d be interested to hear suggestions.








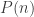 so that the amount of time to solve any instance of the problem with an input of length
so that the amount of time to solve any instance of the problem with an input of length  by 2. We call a problem a P problem if it has an algorithm that solves it in polynomial time.
by 2. We call a problem a P problem if it has an algorithm that solves it in polynomial time.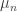 on the instances of the problem of length
on the instances of the problem of length 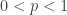 , and we choose some positive integer
, and we choose some positive integer  . In fact, we have the following theorem (which is not quite the best possible):
. In fact, we have the following theorem (which is not quite the best possible):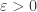 , we have the following:
, we have the following:  , then the probability that the graph is connected goes to 1, as
, then the probability that the graph is connected goes to 1, as 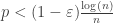 , then the probability that the graph is connected goes to 0, as
, then the probability that the graph is connected goes to 0, as  is a constant. Then:
is a constant. Then: , then with high probability all the connected components are small: they have size
, then with high probability all the connected components are small: they have size 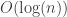 .
.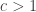 , then with high probability there is exactly one large connected component, of size
, then with high probability there is exactly one large connected component, of size 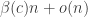 , for some number
, for some number  , and the rest of the connected components have size
, and the rest of the connected components have size 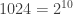 . And the proportion of groups with 2-power order will only increase to 1 as we go further.
. And the proportion of groups with 2-power order will only increase to 1 as we go further.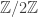 . As we all learned when we were very young and trying to assemble jigsaw puzzles, there are lots of ways of putting together many small pieces, but there are not so many ways of putting together a few large pieces. And this is just as true of groups as it is of jigsaw puzzles.
. As we all learned when we were very young and trying to assemble jigsaw puzzles, there are lots of ways of putting together many small pieces, but there are not so many ways of putting together a few large pieces. And this is just as true of groups as it is of jigsaw puzzles. , even though they contain the same number of factors in their composition series. In fact, there are 408,641,062 of order 1536, which is only roughly 40 times as many as there are groups of order
, even though they contain the same number of factors in their composition series. In fact, there are 408,641,062 of order 1536, which is only roughly 40 times as many as there are groups of order  (as opposed to nearly 5000 times for 1024). I would like to understand this discrepancy, but I’m not there yet.
(as opposed to nearly 5000 times for 1024). I would like to understand this discrepancy, but I’m not there yet. versus
versus  when
when 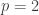 and
and  , there are 14 groups of order 16, 15 of order 24, 14 of order 40, 13 of order 56, and so forth. Similarly, when
, there are 14 groups of order 16, 15 of order 24, 14 of order 40, 13 of order 56, and so forth. Similarly, when  , there are 51 groups of order 32, 52 of order 48, 52 of order 80, and 43 of order 112. Since I don’t know any exciting examples of groups of order
, there are 51 groups of order 32, 52 of order 48, 52 of order 80, and 43 of order 112. Since I don’t know any exciting examples of groups of order  for
for  be a binary digit, so either 0 or 1. To encrypt it, we choose integers
be a binary digit, so either 0 or 1. To encrypt it, we choose integers 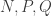 . I’ll explain how they are to be related (i.e. how big they are) later. To encrypt
. I’ll explain how they are to be related (i.e. how big they are) later. To encrypt 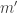 be a random
be a random  -digit number whose last digit is
-digit number whose last digit is  ). Also, pick a random
). Also, pick a random  -digit binary number
-digit binary number  . Encrypt
. Encrypt 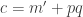 .
. is easy if we know
is easy if we know 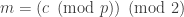 , where
, where  means the unique integer from 0 to
means the unique integer from 0 to 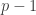 congruent to
congruent to  and then setting
and then setting 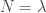 ,
,  , and
, and 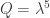 . These choices don’t matter too much, and indeed I might suggest making
. These choices don’t matter too much, and indeed I might suggest making 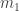 and
and 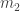 , with ciphertexts
, with ciphertexts 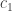 and
and 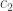 , respectively, then
, respectively, then  and
and  are encrypted versions of
are encrypted versions of  and
and 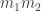 , respectively. (Note that I say “encrypted versions” rather than “the encrypted versions,” because there are many ways to encrypt the same message due to the random choices of
, respectively. (Note that I say “encrypted versions” rather than “the encrypted versions,” because there are many ways to encrypt the same message due to the random choices of 



